첫 프로젝트, 부하테스트
개요
첫 프로젝트의 개발이 끝났고, 서버에 배포까지 준비가 되었다. 배포된 서버는 cloud 서버가 아니고 cafe24에서 구매한 서버이다. 그리하여 오픈 전에 성능을 한번 테스트해보고 싶었다. 부하테스트란 것은 동시접속 유저를 얼마나 수용할 수 있는지 테스트하는 것이다. 그로써 문제점을 확인하고 솔루션까지의 과정이다.
- 테스트 시나리오 작성
- 테스트 툴 선정
- 테스트 실행
- 문제점 파악
- 솔루션
과정은 위처럼 실행했다.
테스트 시나리오 작성
본인같은 경우에는 가장 많이 부하가 걸릴 것으로 예상되는 시나리오 4 가지 정도만 간추려서 테스트했다. 프로젝트 개발할 때 리스트 같은 경우 여러 앱들이 동일한 데이터테이블 형식을 사용했어서 매일 같은 시간에 사용할 만한 리스트를 보는 시나리오, batch를 돌릴때 현재 batch가 얼마나 서버의 리소스를 차지하고 앞으로 얼마나 더 수용할지에 대한 시나리오, push를 보내는 celery, redis의 사용량 이렇게 시나리오를 작성했다.
테스트 툴 선정
처음 부하테스트를 시작하는 것이어서 유료툴을 써보기엔 너무 사전지식이 부족해 최대한 사용하기 편하면서 무료인 것을 찾기 시작했다. 리서치를 열심히 해보니 Jmeter, ngrinder,
locust 이렇게 가장 많이 알려진 툴을 사용한다고 하여 알아보았는데, Jmeter 경우엔 레코딩이 가능했지만 사용하기엔 쓸데 없는 것까지 레코딩을 해버려서 불편했고 테스트 스크립트도
java를 사용해서 나에겐 적합하지 않았다. jmeter를 사용해보니 간단하면서 테스트 스크립트도 빠른 시간내에 짤 수 있는 것이
필요하다고 느꼈다. 그래서 사용했던 것이 locust였다. locust는 비교적 사용도 정말 간단했고 우선 python 기반 스크립트라 최고였다.
locust docs: https://docs.locust.io/en/stable/
Locust
설치
(ksh) C₩windows₩~ : pip install locust
이 툴 같은 경우 쓰레드가 부하를 일으키기 때문에 PC 1대가 부하를 CPU 이상으로 일으킬 수 없다.
실제로 테스트 해봤을때 PC 1대에서 16 명치의 부하를 일으키는 것과 PC 4대에서 16 명치의 부하를 일으키는 것의 시간차이를 보면 차이가 나기 때문에 동시에 접속하고, 요청하고 데이터를 받는 시나리오에서는 적합하지 않다.
그래서 있던 기능이 master와 slave 였다. master에서는 UI와 결과를 보기위한 서버같은 기능을 하는 것이고 slave에서는 실제 부하를 일으키는 기능을 한다. 그렇게 해서 본인은 사용가능한 PC가 6 대 정도 되어서 5 대에서 8 개씩 slave를 띄웠고, 1대의 PC에서 UI와 서버 리소스 모니터링을 하였다. 내가 사용했던 PC는 core가 4 개짜리였는데 8 개의 slave를 초과하면 연결이 끊겨서 1 대당 8개의 slave를 띄웠다.
Master 먼저 부하를 일으킬 스크립트를 작성하자.
from locust import HttpLocust, TaskSet, TaskSequence, seq_task, task, events
from locust.main import runners
from locust.exception import StopLocust
def Getnotice(self):
response = self.client.get('/notice/list2/') # ‘/noitce/list2/’ get 요청할 url주소
print("getnotice") #액션에 대한 로그찍기
if response.status_code != 200 : # 200은 요청의 성공 코드
raise runners.locust_runner.quit() # 요청이 성공하지 않으면 부하생성 종료 -> 실패한 시점을 알기위해서 중지
def Postcommute(self):
response = self.client.post('/commute/list/',{'local':'(lat:100, lng:100)','condition':'외근', 'reason':'testdata'})
# html page의 post할 form의 값들을 지정해준다.
print("post /commute/list/")
if response.status_code != 200 :
raise runners.locust_runner.quit()
def get_login(self):
response = self.client.get('/login/')
print("getlogin")
if response.status_code != 200 :
raise runners.locust_runner.quit()
class UserBehavior(TaskSequence):
#시작할 때의 task설정
def on_start(self):
get_login(self)
@seq_task( 1 ) #이 데코레이터로 task들의 순서를 지정할 수 있음
def post_login(self):
response = self.client.post('/login/',{'username':'<id>', 'password':'<password>'})
print("로그인")
if response.status_code != 200 :
raise runners.locust_runner.quit()
@seq_task( 2 )
def main(self):
response = self.client.get("/")
print("메인페이지")
if response.status_code != 200 :
raise runners.locust_runner.quit()
@seq_task( 3 )
def commute(self):
Getcommute(self)
@seq_task( 4 )
def pcommute(self):
Postcommute(self)
@seq_task( 5 )
def stop(self):
self._sleep( 100000 ) # 기록 저장을 위한 중지
class WebsiteUser(HttpLocust):
task_set = UserBehavior # task 지정
min_wait = 1000
max_wait = 5000
나는 시나리오를 이렇게 작성하였다. 각 코드에 대한 건 공식 document에 잘 나와있으니 참고!!
master server 키는법
(ksh) C₩windows₩~ : locust -f <locust 스크립트 파일.py>--master --host=<테스트할 도메인 이름>
Slave
(ksh) C₩windows₩~ : locust -f <locust 스크립트 파일.py> --slave --master-host=<master pc ip>
master pc ip는 테스트할 서버의 ip 주소가 아닌, master server를 켜놓은 pc의 ip주소다. 이렇게 slave를 하나씩 만들어주면 너무 힘들 것 같았다. conda 켜서, 가상환경 켜주고 저 명령어를 160 번 칠 생각을 하니 부하테스트를 포기하고 싶어졌다. 그래서 window batch 파일을 만들었다.
### conda.bat
@echo off
title CMD 실행
cmd /k "C:\ProgramData\Anaconda3\Scripts\activate.bat C:\ProgramData\Anaconda3 &&
activate ksh && locust -f locustfile.py --slave --master-host=192.168.0.73"
위에 C:\부분만 설명을 좀 더하자면..
- C:\ProgramData\Anaconda3\Scripts\activate.bat C:\ProgramData\Anaconda
- conda prompt를 실행해준다
- activate ksh
- 가상환경 활성화
- locust -f <테스트 스크립트="" 파일명="">.py --slave --master-host=
- slave 활성화
이렇게 이루어진다. window를 쓰는 사람 중 환경변수에 conda를 추가해놓은 분은 1번 과정을 생략하여도 좋다.
테스트 실행
port를 지정해주지 않으면 default로 8089 번 포트를 사용한다.
 url 창에 localhost:8089 입력하여 접속하면 위와 같은 페이지가 뜰 것이다.
Number of users to simulate : 시뮬레이션할 user 의 수
Hatch Rate : 초당 요청할 user 의 수
위에서도 말했지만 슬레이브 수를 늘리지 않으면 동시접속의 의미가 없어 Hatch Rate는 최대
slave 수와 동일하게 설정해주면 된다.
이렇게 설정 후 실행 하면 아래와 같은 페이지가 실행될 것이다.
url 창에 localhost:8089 입력하여 접속하면 위와 같은 페이지가 뜰 것이다.
Number of users to simulate : 시뮬레이션할 user 의 수
Hatch Rate : 초당 요청할 user 의 수
위에서도 말했지만 슬레이브 수를 늘리지 않으면 동시접속의 의미가 없어 Hatch Rate는 최대
slave 수와 동일하게 설정해주면 된다.
이렇게 설정 후 실행 하면 아래와 같은 페이지가 실행될 것이다.

- Type : get 또는 post 요청
- Name : 요청할 Url 주소
- Requests : 요청 개수
- #Fails : 요청 개수 중 실패한 개수
- Median (ms) : response(응답) 시간의 중간값
- Average(ms) : 평균 response(응답) 시간
- Min (ms) : 가장 빨리 response(응답)된 시간
- Max (ms) : 가장 늦게 response(응답)된 시간
- Average size (bytes) : 평균 데이터 크기
- Current RPS : 최근 1 초당 응답수
메뉴 중 Charts로 이동하면
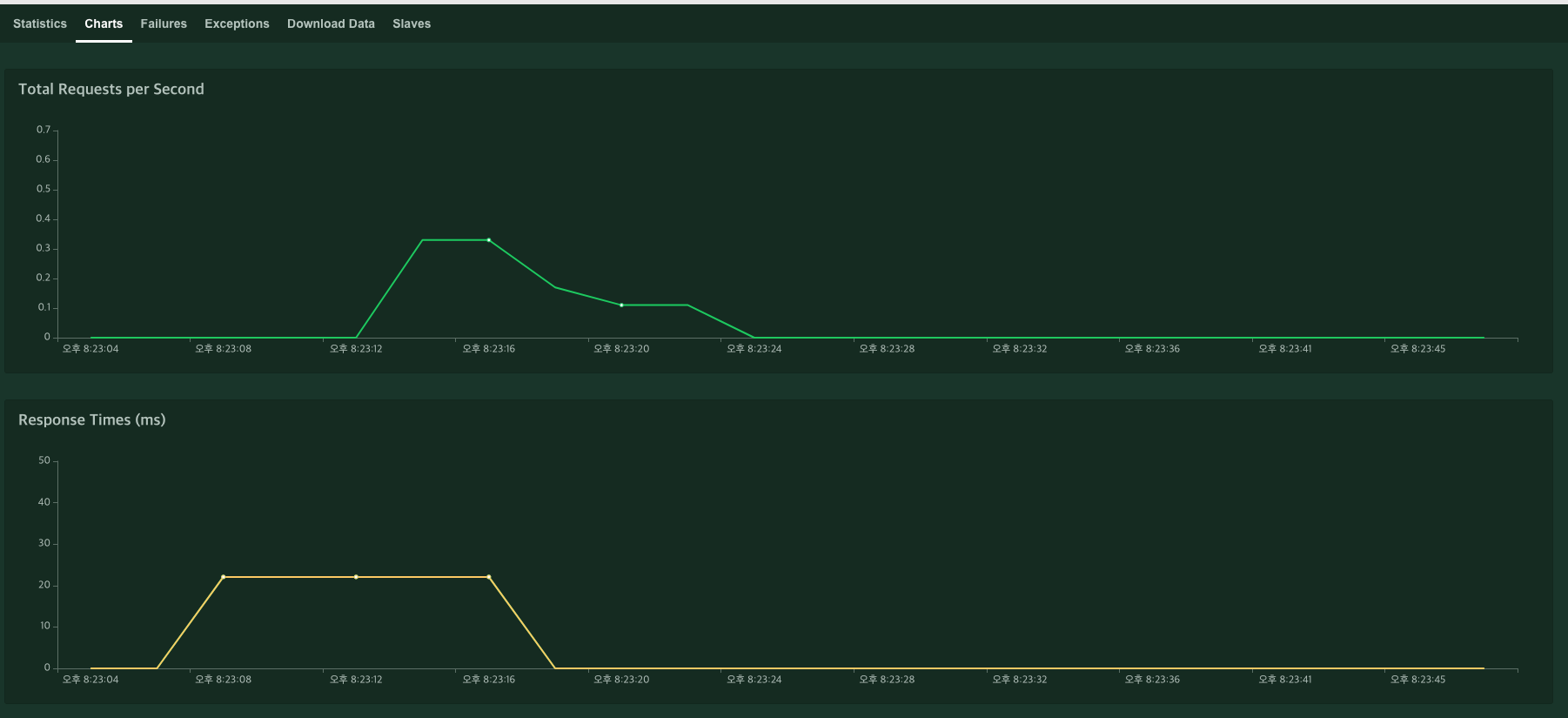 이처럼 차트형식으로 RPS, 평균 응답시간, User의 수를 차트 형식으로 볼 수 있다.
Failures 메뉴에서는 요청 실패에 대한 로그를,
이처럼 차트형식으로 RPS, 평균 응답시간, User의 수를 차트 형식으로 볼 수 있다.
Failures 메뉴에서는 요청 실패에 대한 로그를,
 Exceptions 메뉴에서는 locust 서버 exception 로그를,
Exceptions 메뉴에서는 locust 서버 exception 로그를,
Download Data 메뉴에서는 테스트 실행 결과, 요청당 응답 시간 비율, 에러 로그를 csv파일로
받을 수 있다.
부하 테스트 실행 전 token 제거해주기
우리가 만든 django 에서는 django 를 쓰는 이유로도 불릴 csrftoken이 middleware에서 요구된다. 이 csrftoken을 post 요청할 때마다 저장하고 불러와야 하기 때문에 굉장히 번거로워진다. 그래서 본인은 csrf middleware를 테스트 실행 전에 아예 제거해버리고 시작했다. 전에 ajax때문에 django의 csrf_exempt 데코레이터를 써서 하나의 view에서만 강제하지 않게 하는 법을 알고 있지만 여러번 반복하기 싫어서 global로 적용하는 방법을 찾아봤다. settings.py 에 가보면,
MIDDLEWARE = safe_get('middleware', [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'debug_toolbar.middleware.DebugToolbarMiddleware',
])
이렇게 Middleware들이 주욱 나열 되어있다. 참조 : https://docs.djangoproject.com/en/1.8/_modules/django/middleware/csrf/ ‘django.middleware.csrf.CsrfViewMiddleware’ 이 부분을 주석 처리하면 csrf token을 사용하지 않을 줄 알았다. 하지만 결과가 같아서 찾아보니, middleware를 아예 만들어서 강제하지 않게끔 하는 방법이 나와있어 사용했다.
class DisableCSRF(object):
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
setattr(request, '_dont_enforce_csrf_checks', True)
response = self.get_response(request)
return response
프로젝트 폴더에 python 파일을 하나 만들어 위처럼 작성해주자. 요청에 csrf check를 하지 않게 속성을 담아주고, 그에 대한 응답을 하게끔 해주는 역할이다. 본인은 csrfexempt.py라고 파일을 만들어주었다. 이 후 settings.py 에 가서 Middleware 칸에 추가해주자.
MIDDLEWARE = safe_get('middleware', [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
#'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'debug_toolbar.middleware.DebugToolbarMiddleware',
'glocal.csrfexempt.DisableCSRF'
])
이렇게 하면 global로 csrf check를 무시하고 사용가능하다.
문제점 파악
문제점을 파악하는데 정말 힘이 많이 들었다. 확인해야 할 것들이 내가 구축했던 gunicorn log, nginx log, 서버 리소스 사용량, django, DB 등등 너무 많았다. 먼저 서버 리소스 사용량을
확인했었는데 우선 간단하게 볼 수 있는 top기능이 있었지만 본인 경우에는 보고서를 작성해야 하기때문에 레코딩을 해주고 모니터링이 간단한 것을 찾았었다. dstat라는 것을 사용했었는데 레코딩을 하면 csv파일로 저장을 해주고 본인은 엑셀을 사용하여 차트를 만들어 정리하였더니 좀 더 편하게 볼수있어 좋았다. 조금 허접하긴 하지만 보기에는 편했다.

내가 테스팅한 결과에서는 동시접속자 수를 40 명정도를 생성했었는데 요청을 다 실패했었다.
리소스 모니터링 결과 cpu든 memory든 조금의 변화량밖에 없어 뭐가 문젤까 찾지 못했었는데 DB의 로그를 확인하니 query문을 10 개를 요청한다고하면 동일한 query문이 200 개 가량이 오고있어 문제였다. 전체적인 문제점들을 정리하면,
- 데이터테이블 사용 시, view에서 query의 전체를 들고와서 paging
- query를 중복으로 불러옴
- DB쿼리문의 존재확인을 length를 사용
솔루션
- select_related, prefatch_related 활용
- 템플릿에서만 pagination을 하는 게 아닌 django에서도 pagination사용
- query문 중복사용하지 않을 것 처음 코드를 짤때, 이후 어떤 일이 벌어질지 몰랐지만 부하테스트를 하고 눈에 확실하게 보이는 결과를 확인하니 모델링, 중복되는 코드들의 심각성을 알 수 있었다.